I will document this properly in the appropriate time.
View all quiz results at the repository here
Qwiklabs - Handling Files
#!/usr/bin/env python3
import csv
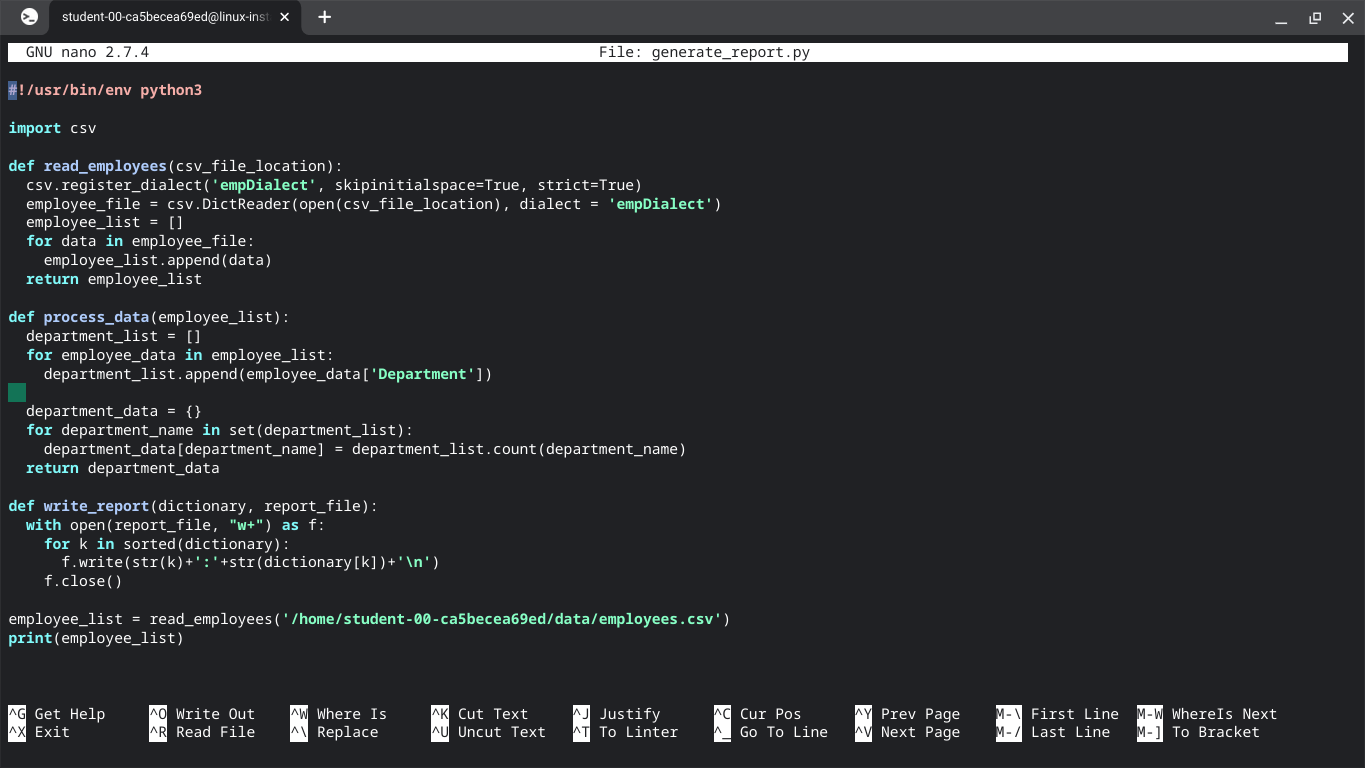
def read_employees(csv_file_location):
csv.register_dialect('empDialect', skipinitialspace=True, strict=True)
employee_file = csv.DictReader(open(csv_file_location), dialect = 'empDialect')
employee_list = []
for data in employee_file:
employee_list.append(data)
return employee_list
def process_data(employee_list):
department_list = []
for employee_data in employee_list:
department_list.append(employee_data['Department'])
department_data = {}
for department_name in set(department_list):
department_data[department_name] = department_list.count(department_name)
return department_data
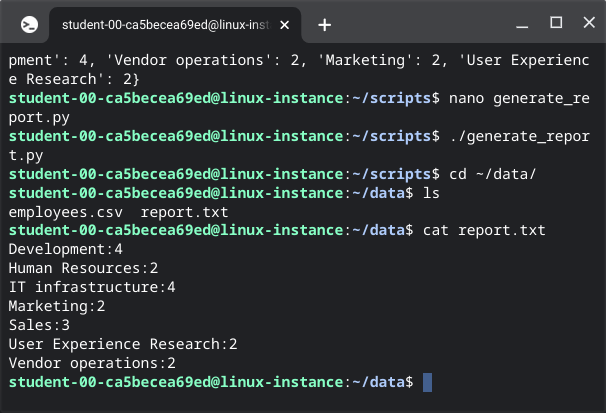
def write_report(dictionary, report_file):
with open(report_file, "w+") as f:
for k in sorted(dictionary):
f.write(str(k)+':'+str(dictionary[k])+'\n')
f.close()
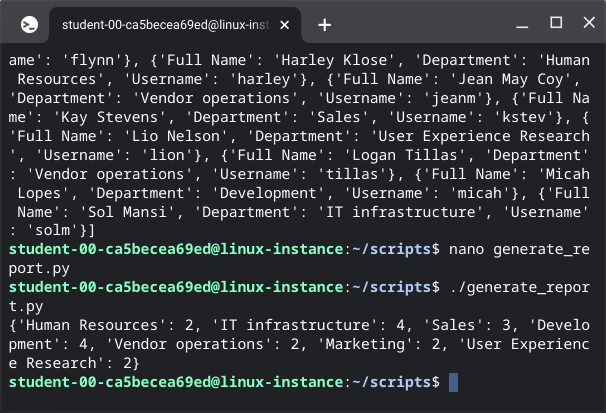
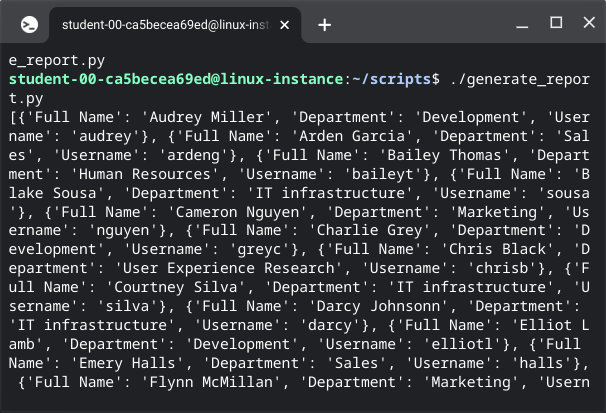
employee_list = read_employees('/home/<student-lab-id>/data/employees.csv')
def process_data(employee_list):
department_list = []
for employee_data in employee_list:
department_list.append(employee_data['Department'])
department_data = {}
for department_name in set(department_list):
department_data[department_name] = department_list.count(department_name)
return department_data
dictionary = process_data(employee_list)
def write_report(dictionary, report_file):
with open(report_file, "w+") as f:
for k in sorted(dictionary):
f.write(str(k)+':'+str(dictionary[k])+'\n')
f.close()
write_report(dictionary, '/home/<student-lab-id>/test_report.txt')
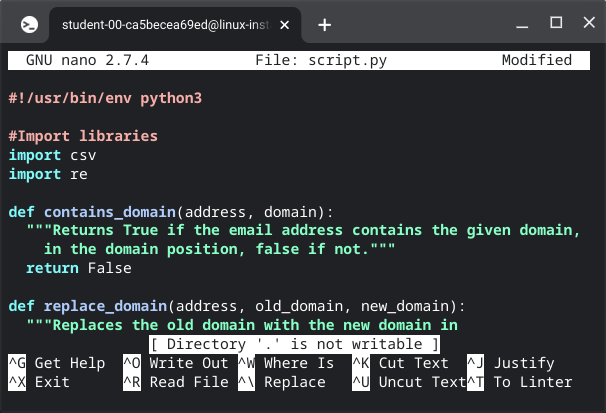
Qwiklabls- Working With Regular Expressions
#!/usr/bin/env python3
#Import libraries
import csv
import re
def contains_domain(address, domain):
"""Returns True if the email address contains the given,domain,in the domain position, false if not."""
domain = r'[\w\.-]+@'+domain+'$'
if re.match(domain,address):
return True
return False
def replace_domain(address, old_domain, new_domain):
"""Replaces the old domain with the new domain in the received address."""
old_domain_pattern = r'' + old_domain + '$'
address = re.sub(old_domain_pattern, new_domain, address)
return address
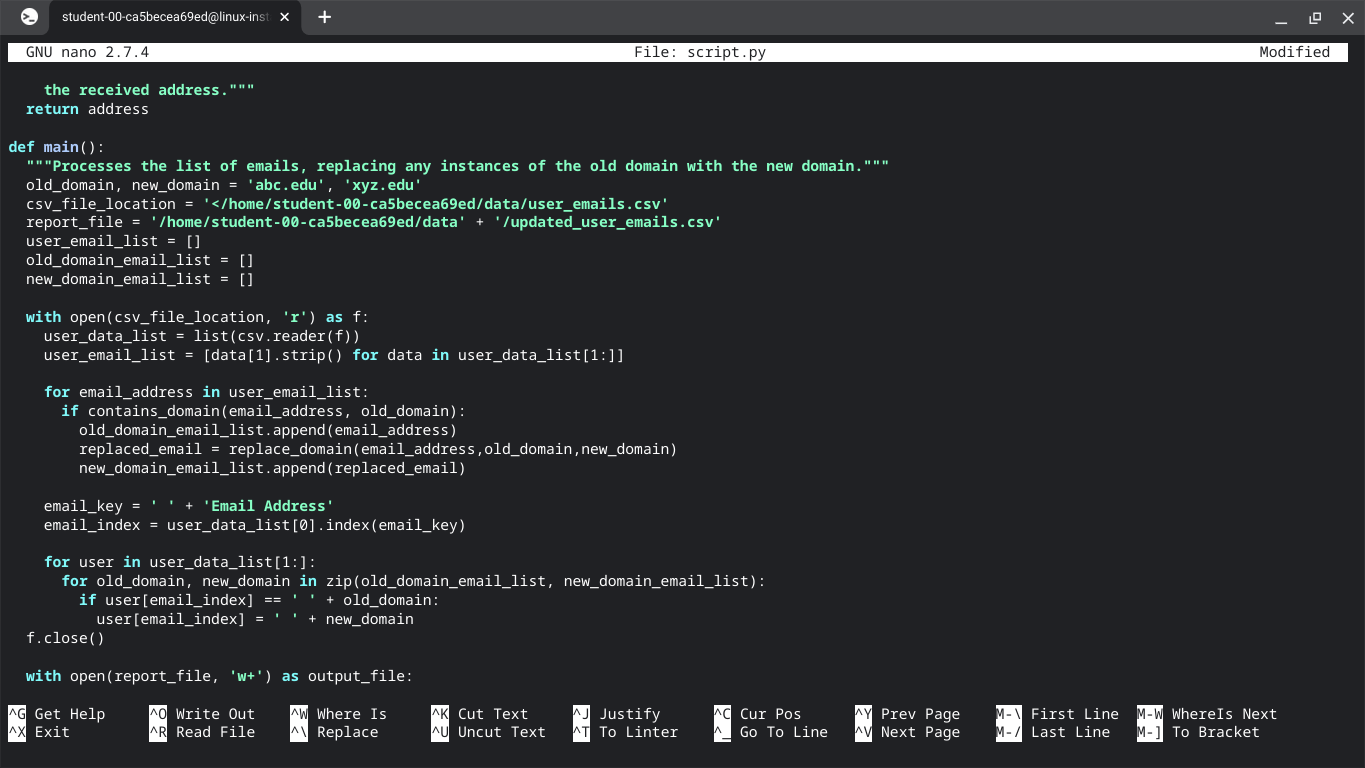
def main():
"""Processes the list of emails, replacing any instances of the old domain with the new domain."""
old_domain, new_domain = 'abc.edu', 'xyz.edu'
csv_file_location = '/home/<student-lab-id>/data/user_emails.csv'
report_file = '/home/<student-lab-id>/data' + '/updated_user_emails.csv'
user_email_list = []
old_domain_email_list = []
new_domain_email_list = []
with open(csv_file_location, 'r') as f:
user_data_list = list(csv.reader(f))
user_email_list = [data[1].strip() for data in user_data_list[1:]]
for email_address in user_email_list:
if contains_domain(email_address, old_domain):
with open(report_file, 'w+') as output_file:
writer = csv.writer(output_file)
writer.writerows(user_data_list)
output_file.close()
with open(report_file, 'w+') as output_file:
writer = csv.writer(output_file)
writer.writerows(user_data_list)
output_file.close()
main()
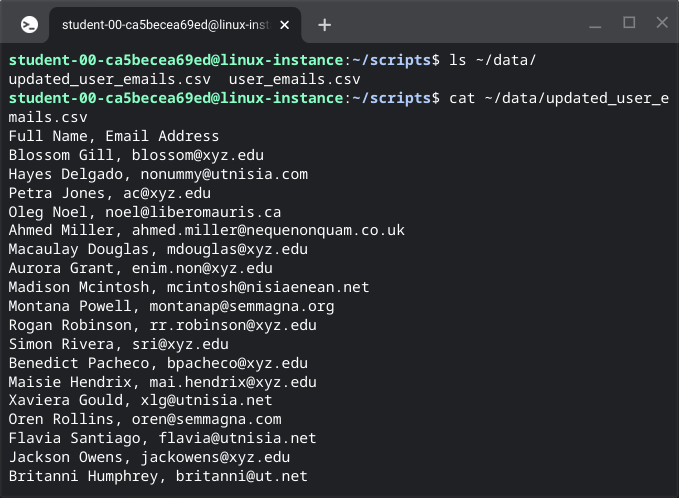
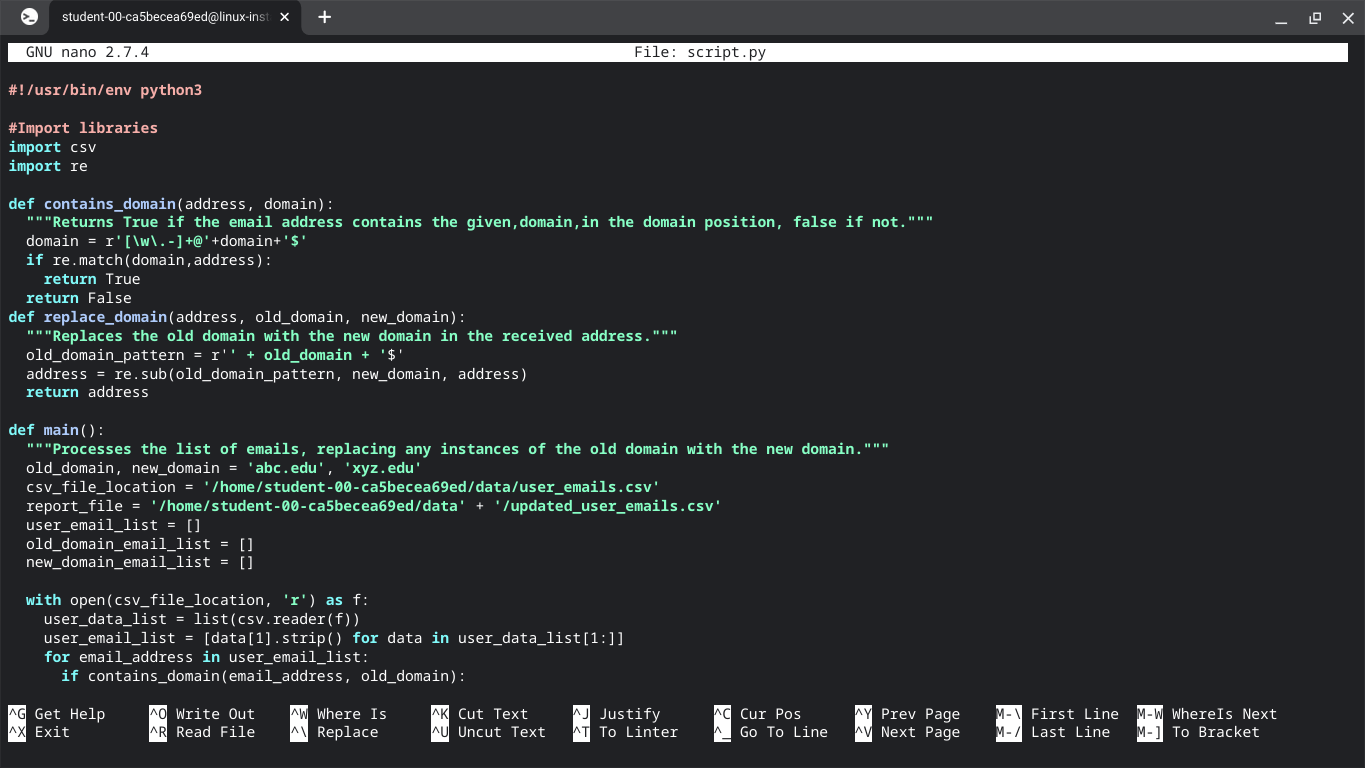
Qwiklabs - Working With Log Files
#!/usr/bin/env python3
import sys
import os
import re
def error_search(log_file):
error = input("What is the error? ")
returned_errors = []
with open(log_file, mode='r',encoding='UTF-8') as file:
for log in file.readlines():
error_patterns = ["error"]
for i in range(len(error.split(' '))):
error_patterns.append(r"{}".format(error.split(' ')[i].lower()))
if all(re.search(error_pattern, log.lower()) for error_pattern in error_patterns):
returned_errors.append(log)
file.close()
return returned_errors
def file_output(returned_errors):
with open(os.path.expanduser('~') + '/data/errors_found.log', 'w') as file:
for error in returned_errors:
file.write(error)
file.close()
if __name__ == "__main__":
log_file = sys.argv[1]
returned_errors = error_search(log_file)
file_output(returned_errors)
sys.exit(0)